

推動我國大模型開源創新生態建設的挑戰與建議
2024-09-24 16:20
來源:中國網·中國發展門戶網




中國網/中國發展門戶網訊 大模型的涌現和同質化能力不僅將大幅提升人類的認知效率,還將引發經濟、社會、文化等領域的變革與重塑。世界主要國家爭相加快推進大模型發展,探索大模型發展的有效路徑成為當前關注的焦點。美國大模型開源創新生態的繁榮是其技術和產業發展始終走在前列的重要原因。一方面,大量開源的基礎大模型層出不窮,不斷推動底層技術性能的進步。例如,以開放式大語言預訓練模型OPT、GPT-NeoX-20B等為代表的早期開源大模型的推出促進了開源社區對大模型的研究,美國OpenAI公司推出的GPT大模型的早期版本也完全開源。開源情況下,研發者能直接接觸具有前沿性能的大模型,通過對已有開源大模型進行微調或者采用更大、更高質量數據集及更大規模模型參數創建性能更優的基礎大模型,推動開源大模型技術性能快速進步。另一方面,以開源大模型為基礎的開源應用不斷出現,推動大模型產業的壯大。以AI(人工智能)繪畫生成工具Stable Diffusion為代表的開源大模型形成了廣泛的用戶社區,衍生出極具多樣性的應用場景,打開了大模型產業應用的想象空間。
與之相比,盡管我國部分大模型性能突出,但大模型上下游產業鏈各個環節缺乏協同,存在競爭無序和資源浪費現象。一方面,存在大量未開源的低質量大模型,導致低水平重復建設,難以真正推動我國大模型的發展;另一方面,大模型上游涉及的數據、算力,以及下游涉及的應用,均未能建立起真正的開源開放生態,阻礙了我國大模型產業的發展。這一狀態將影響我國大模型產業的可持續發展,難以保障我國科技安全和產業鏈安全。
經驗表明,開源創新生態能幫助匯聚全球開發者智慧以推動大模型技術進步,并激發社會創新活力加快大模型應用落地,能夠憑借開源開放這一全球公認的突破科技壟斷或制約的有力手段推動我國大模型及相關產業發展。然而,現有研究缺乏對大模型開源創新生態的關注。本文從上游供應生態、下游應用生態和治理協調生態3個維度回顧開源創新生態構建的相關經驗;從關系到大模型性能的底層算法、數據和算力維度,大模型下游產業生態搭建現狀,大模型開源治理體系,以及政府系統協同政策推動方面,分析目前我國大模型開源創新生態構建存在的問題;在此基礎上,提出構建開源創新生態推動大模型產業發展的相關對策建議。
開源創新生態對發展我國大模型的重要意義
大模型是指包含超大規模參數(通常在10億個以上)的深度學習或機器學習模型,具有基礎資源門檻高、產業集群效應強和潛在壟斷性大等特點,后發企業難以快速形成行業積累實現追趕。開發貢獻者、行業開源者、開源使用者等多元創新主體基于開放、協作和共享理念,圍繞數字基礎設施構建協同創新和價值共創的開源創新生態,有助于整合資源降低大模型研發成本,匯聚眾智促進大模型技術迭代演進,形成相對競爭優勢,從而有效推動大模型的發展與趕超。
整合底層基礎資源,降低行業研發成本
大模型往往需要大量的訓練數據、多種不同的學習任務及強大的計算資源支撐,致使訓練成本巨大(例如,GPT-3的訓練據估計花費超過4 600萬美元)。開源創新生態一方面能夠促進基礎數據資源的自由流動和高速聚集整合,從頂層設計上擴大數據規模、提高數據質量和多樣性,加強中文數據的標準化集成和持續積累優化,為大模型算法和技術研發提供數據保障;另一方面可以提供基礎的大模型算法技術并促進算力基礎設施的共建共用,以低成本的開放協作模式推動開發者充分探索參數、數據和算力組合情況下的性能表現,推動大模型整體的改進創新。由此,開源創新生態能夠通過數據共享、算法開源、算力基礎設施共建共用等方式,解決大模型研發和應用中單一機構難以完全滿足數據、算法和算力資源要求的問題,從而降低企業乃至全社會商業化大模型的成本。可見,開源創新生態有助于打破壟斷、降低大模型技術研發和優化的競爭壁壘,提高大模型數據和算力等基礎設施的使用效率,加速推動我國大模型技術的創新發展及快速應用。
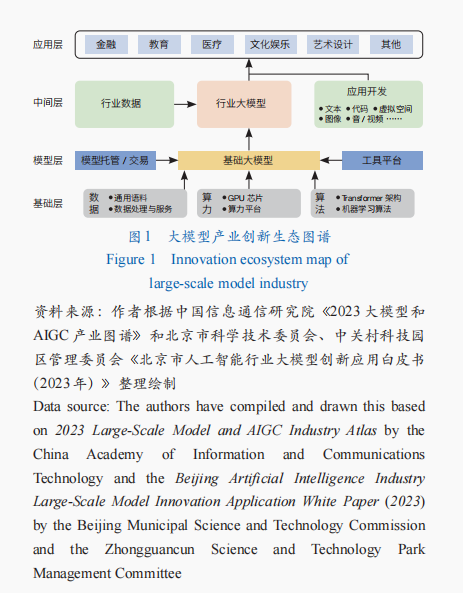
推動技術透明可信,促進技術迭代創新
大模型高昂的研發成本限制了學術界、非營利組織和較小規模工業實驗室研究人員對大模型的研究和訪問;不僅如此,閉源的大模型研發過程大幅降低了技術透明度和可信度,難以匯聚社會多方力量深化對大模型技術相關道德倫理風險的認知,進而阻礙大模型技術在各行業中的落地應用。大模型開源創新生態能降低各方潛在參與者參與大模型研究的難度,使得研究者更好理解大模型工作原理,提升社會對大模型應用接受度。同時,大模型的發展具有較強的產業集群效應(圖1),開源創新生態有助于數據、算法和算力全方位協同,供應商、從業人員、平臺、服務、數據和生產有效結合,加快大模型在各個產業中的應用,促進從模型層、中間層到應用層的多元主體價值共創。開源開放有助于建立社會對大模型技術的信任,推動不同級別大模型在各個行業的應用,而通過廣泛應用場景積累的技術需求和技術問題將反哺大模型技術本身,推動大模型技術迭代發展。
以非對稱競爭優勢,打破潛在行業壟斷
開源開放是全球公認的突破科技壟斷或制約的有力手段,推動大模型開源創新生態建設不僅將為我國大模型技術提供新的發展機遇,還有望推動我國大模型產業出海,打破潛在行業壟斷,化被動為主動。“微軟Windows+OpenAI大模型+英偉達GPU”通過強強聯合綁定形成新的壟斷生態,阻礙我國信創產業發展、威脅我國信創產業的科技安全和產業鏈安全。大模型開源創新生態能充分發揮我國在開源芯片等領域的技術優勢,并通過集中攻關開辟新賽道形成非對稱競爭優勢。同時,推動我國大模型開源創新生態在全球大模型生態中占據一席之地,可為我國大模型技術在其他國家的應用提供良好契機。這能夠打破國外大模型的潛在壟斷生態,擺脫對歐美科技基于封閉知識產權的“非對稱依賴”。既往發展經驗表明,構建開源創新生態不僅能推動上下游相關產業健康有序協同發展,還能掌握一定技術發展路線話語權和主導權,使我國軟件產業牢牢嵌套在國際整體生態之中,打破制約壟斷。
構建開源創新生態的國際經驗
開源運動從軟件代碼的公開協作開始,其開放共享的理念逐步擴散到計算機及相關產業的方方面面。越來越多來自全球的個人開發者和組織積極投身到開源運動中,數十年間國際上圍繞開源逐步構建起穩固完善的上游供應生態、豐富多元的下游應用生態和公開有效的治理協調生態,其發展經驗值得借鑒以構建我國大模型開源創新生態。
構建穩固完善的開源上游供應生態
上游供應生態的發展為開源項目的技術進步和持續創新奠定了基礎。
支持開發者的開發工具和資源是上游供應生態的關鍵組成部分。開源項目可以為開發者提供友好的協作工具、文檔和教育資源,以幫助他們理解和使用項目,提高開發效率并確保代碼質量。在國際大模型開源過程中,這些開發工具和資源也被大量采用。例如,開源分布式版本控制系統Git為開發者提供了管理代碼版本、協作開發和代碼審查等功能,其廣泛應用使得開發者能夠更好地管理和追蹤代碼的變更,同時也有助于團隊間的協作和合作。集成開發環境(IDE)和編程語言工具鏈等開發工具為開發者提供了高效的編寫環境,Visual Studio Code、Eclipse、PyCharm等開放的集成開發環境提供了豐富的功能和插件生態系統,使得開發者能夠高效地編寫、測試和調試代碼。
支持開發者的數據是上游供應生態的關鍵一環。作為軟件開發的重要底座,數據對應用性能訓練的提升至關重要。開放的數據集不僅有利于構建公開透明的協作環境,同時能大幅降低技術開發前期成本及開發門檻,推動技術進步。目標檢測、自動駕駛、人臉識別、自然語言處理、文本監測、醫療等方向均有大量經典開源數據集,例如人臉識別領域的YouTube Face Database包含1595個不同人的3425個視頻,總計671.41 GB數據,能夠幫助訓練優化人臉識別算法,減少開發人員在技術早期開發過程中遇到的困難。這些經典開源數據集也是大模型產生之初可靠的數據來源。
打造豐富多元的開源下游應用生態
下游應用生態包括開源軟件的應用和集成,以及相關的商業生態系統。豐富多元的下游應用生態能吸引更多開發者和企業使用、擴展和創造基于開源項目的應用,促進相關產業的繁榮發展。以往的開源下游應用生態構建經驗值得我國在打造大模型開源下游應用生態過程中學習。
廣泛的用戶和開發者參與,從不同的角度和需求出發為軟件貢獻代碼、提供反饋并解決問題,從而推動軟件本身的發展和改進。例如,Android移動操作系統的成功很大程度上得益于其擁有豐富多樣的下游應用。開發者可以通過使用Android開發工具包(SDK)創建應用程序,并通過Google Play商店這一應用市場將大量涵蓋各種領域和需求的應用程序分發給用戶。由此,Android打造的多元下游應用生態為用戶提供了廣泛的選擇,這種繁榮的應用生態系統吸引了全球范圍內的開發者和企業,推動了Android平臺的發展和創新,促進Android系統產業整體的發展。又如,OpenAI也開放其大模型應用程序接口(API),鼓勵其他開發者將其大模型服務集成進其應用產品中,充分開發下游應用生態。
通過專門的支持機構或社區來提供技術支持、文檔、培訓和社區管理等服務。這可以幫助用戶和開發者更好地理解和使用開源軟件,并解決在實際應用中遇到的問題。例如,開源機器學習框架TensorFlow和PyTorch都有龐大的社區支持和專門的支持機構。這些支持機構提供了官方文檔、教程、示例代碼等資源,幫助用戶和開發者學習和使用這些框架。同時,還通過舉辦培訓課程、開發者大會等活動,促進用戶和開發者之間的交流和合作。
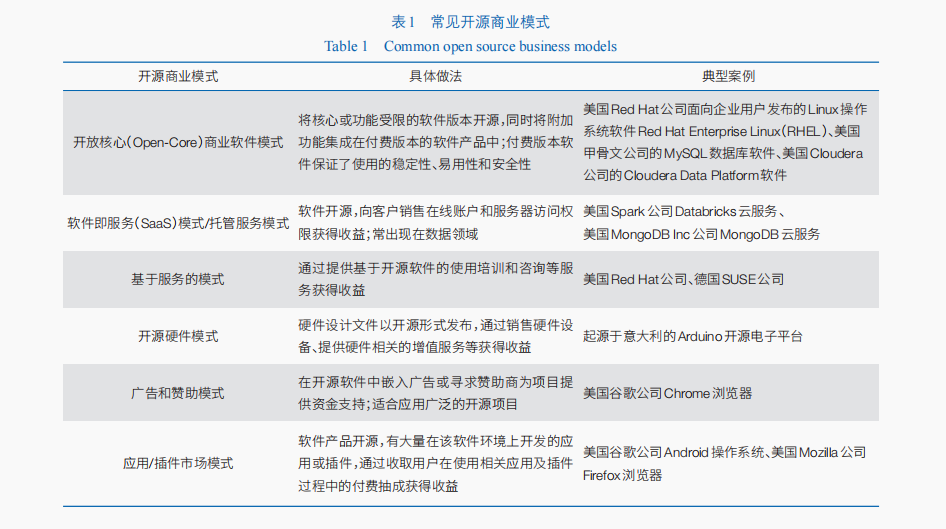
發展基于開源軟件的下游商業生態系統。開源軟件商業生態系統的核心在于開源軟件的產品和服務提供商,他們在開源軟件的基礎上通過提供定制化的解決方案、額外高級功能、代碼托管或整合、搭建并運營插件市場、提供培訓和咨詢等運維服務等模式(表1)來謀求商業回報。經驗表明,開源商業化有助于開源產出成果發揮價值,幫助其實現“價值創造—價值實現—價值分配”的合理閉環。形成有效商業模式的下游開源商業生態系統不僅對開源項目本身的健康可持續發展具有重要作用,還能促進同類技術的持續創新和市場競爭。美國大模型領域也積極探索開源商業化模式,意圖構建起繁榮可持續的開源大模型下游商業生態。例如,美國Stability AI公司通過開發開源大模型Stable Diffusion的商用版本,為客戶提供定制拓展服務來促進大模型的應用。
培育公開有效的開源治理協調生態
開源治理協調生態涉及開源項目的決策、管理和社區參與等方面,開源治理協調生態的健康發展對于項目的長期穩定和社區的繁榮至關重要。主要包括以下3個方面。
公開透明的決策流程和溝通機制能使所有人了解技術路線決策細節,從而對項目建立長期的信任,促進參與和合作。例如,在美國發布的Linux內核社區采用郵件列表作為主要溝通方式,由此使得項目成員能隨時了解項目發展方向和最新動態;通過一系列公開的解釋文檔詳細說明了技術開發相關的決策執行機制和協作模式。所有決策流程和相關信息公開可追溯增強了社區的信任感,鼓勵更多人參與到開源項目貢獻中,從而促進了項目的健康長久發展。
建立有效的沖突解決機制也是構建成功開源治理協調生態中的關鍵一環。例如,位于美國的云原生計算基金會(CNCF)下設技術監督委員會來協調組件之間兼容性沖突,其技術監督委員會成員通過選舉產生,其成員來自供應商、最終用戶等多個方面,能充分代表開源社區內各方的利益,有助于維護社區的和諧與穩定,并推動項目的進展。
良好有效的開源制度設計對開源參與者長期可持續參與到開源項目貢獻之中非常重要。其中,開源許可證是開源制度設計中的關鍵,它決定了如何使用、修改和分發開源軟件。選擇符合項目目標和社區需求的開源許可證能保護貢獻者的權益、推動創新和知識共享。常見的開源許可證包括MIT許可證、Apache許可證和GNU通用公共許可證等。阿聯酋開發的Falcon大模型就采用Apache-2.0許可證,其成為第一個可以免費商用的開源大模型,這將促進其模型在科研及商業化中的應用。
我國大模型開源創新生態建設面臨的挑戰
我國開源創新生態尚處于初步探索階段,社會對開源認知不夠,且缺乏建設開源創新生態的經驗及配套完善的體制機制。大模型作為新興技術和產業,其開源創新生態的建設將面臨更大的挑戰。一方面,我國大模型底層基礎研究能力相對薄弱,數據和算力基礎制約大模型性能提升;另一方面,大模型產業內各類創新主體間未形成有效協同,產業內無序競爭引發亂象叢生。這些挑戰不僅限制了我國大模型進一步的發展應用,更阻礙了我國大模型參與國際競爭,在全球范圍內影響力的輻射擴散。
系統協同政策架構設計缺失
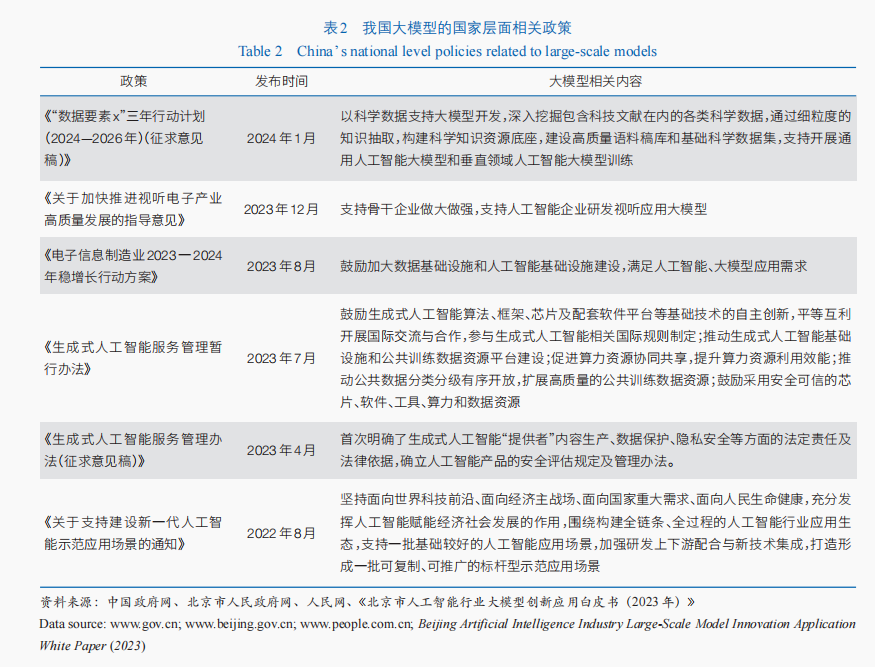
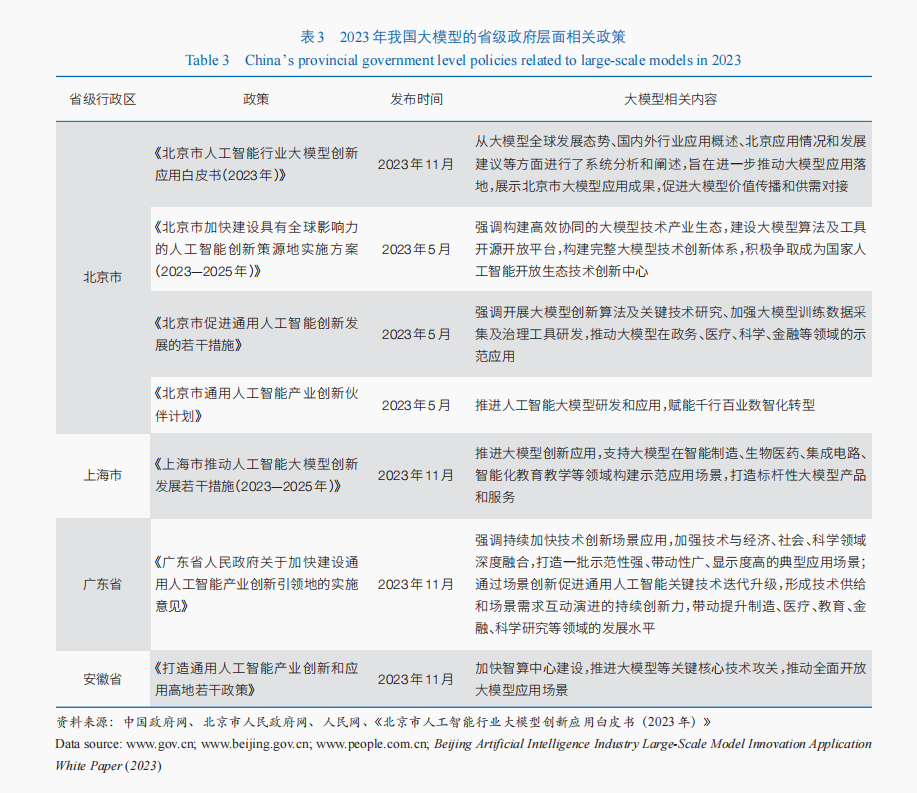
盡管我國在國家層面(表2)及各省級地方政府層面(表3)均高度重視大模型發展,從算力支持、場景開放、技術突破、產品生態等多方面積極出臺大模型產業發展措施,鼓勵大模型應用落地。然而,我國現有政策系統性不足,主要集中在大模型本身,對大模型產業鏈條的其他環節關注不夠,尤其是數字公共產品制度、開源商業化制度等適應開源創新生態的體制機制建設尚不健全,導致產業鏈上下游協同不足,難以滿足建設大模型開源創新生態需求。同時,各部門間缺乏有效信息互通、各地政府間技術要素不流動,政策趨同致使無法形成合力推動人工智能大模型產業整體發展,未充分發揮出對實體經濟的賦能作用。多個部門同時負有促進大模型應用落地、產業繁榮的職責,部門職能存在重疊導致政策間的協調不足,無法充分發揮政策指導促進的作用。
技術能力制約生態形成
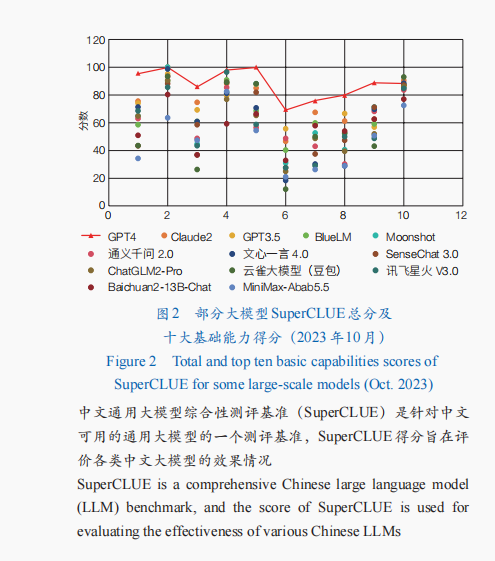
我國大模型整體技術實力與國外頭部企業差距明顯,在算法、人才和科研投入方面與國外頭部企業差距較大,同時部分關鍵核心技術尚未突破,尚未形成促進國產大模型發展的支撐基礎。根據權威測評榜單Super CLUE的評測,截至2023年10月,GPT-4、Claude2和GPT-3.5在基礎模型領域綜合排名前3位(圖2),我國基礎模型在計算、代碼、生成與創作、上下文對話、角色扮演、工具使用方面得分與GPT-4的相應指標相差10分以上,部分指標接近GPT-3.5,僅在中文知識題目方面明顯優于國際模型。大模型廠商技術上的基本同源導致現階段較為相似的模型性能,尚未形成顯著技術性能優勢,同質化嚴重影響了下游應用生態的構建。同時,我國基礎模型缺乏原創性,版本迭代和技術演進高度依賴國外進展。特別是我國目前廣泛應用的主流模型大多基于Transformer架構,而非我國自主研發的架構,在一定程度上制約了我國國產大模型自主創新生態的形成。
數據算力顯著限制技術發展
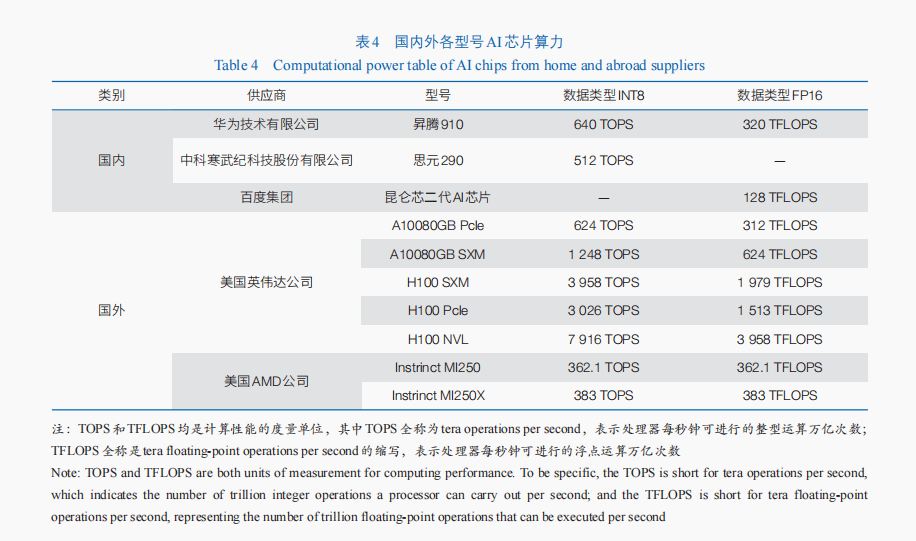
OpenAI、Google人工智能研究團隊相繼證明,人工智能模型的性能隨著模型規模的指數級上升而線性增長,并在模型規模達到某個閾值時對某些問題的處理性能突增,具備涌現能力。這一現象凸顯數據和算力在提升大模型性能中的重要意義。在數據方面,盡管我國已有部分中文開源數據集,但從數據規模和語料質量上均與海外有較大差距,且部分內容較為陳舊,高質量全面完整可信的開放中文數據集匱乏。同時,我國尚未建立有效的數據流通規則和數據供需對接機制,企業獲取數據資源的成本極高。數據產品供應鏈尚不完善嚴重制約了我國大模型的訓練表現。在算力方面,中國、美國在全球算力規模中的份額分別為33%、34%,其中以圖形處理器(GPU)和神經網絡處理器(NPU)為主的智能算力規模方面中國高于美國,分別為39%、31%,具備發展大模型產業的有利基礎。然而,現階段國產GPU性能難以滿足大模型訓練要求,與國際主要采用的英偉達A100芯片存在顯著差距。例如,國產算力最高的昇騰910芯片計算速度(320 TFLOPS)僅與英偉達A100 PCle版本持平,與英偉達H100 NVL版本相差10倍以上(表4)。另外,國產人工智能智算芯片配套的編程環境尚不成熟。與英偉達的并行計算平臺和編程模型(CUDA)工具包相比,我國相應軟件生態建設仍需加強,這是一個投入巨大并且漫長的過程。
創新主體無序競爭制約整體發展速度
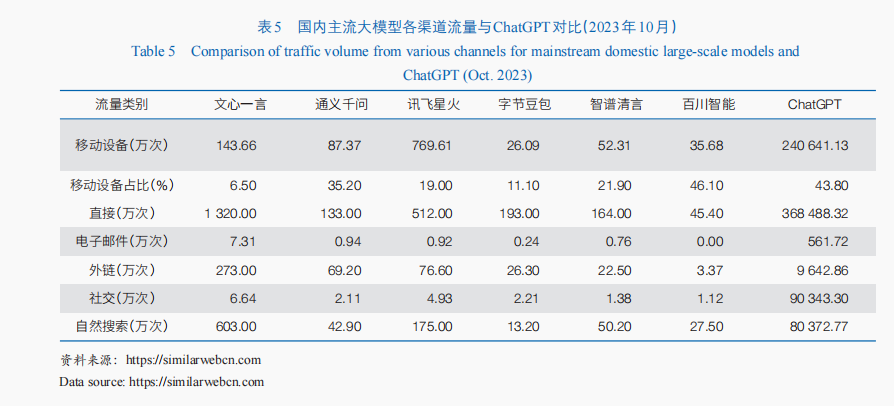
包括:“百模大戰”引發無序競爭,由于數據“孤島”、賽道重疊、市場競爭等原因企業各自為戰,造成資源投入分散、共創共建開源意愿不足等問題。數據顯示,截至2023年10月,我國有互聯網企業(百度、字節跳動、阿里巴巴等)、新興創業公司(百川智能、MiniMax、月之暗面等)、傳統AI企業(科大訊飛、商湯科技等),以及高校科研院所等254家單位開展了通用大模型研發,導致資源碎片化投入,重復低水平建設,計算資源競爭加劇。國產大模型應用軟硬件適配與協同優化尚顯不足,軟硬件生態有待進一步豐富。對比國內外大模型產品應用流量來源,國外大模型來自移動端的用戶流量遠高于國產大模型,且國產大模型產品應用在電子郵件、社交應用程序、自然搜索等外接應用流量上也遠低于ChatGPT(表5)。現有國產大模型尚未探索出合適的大模型開源商業模式。我國在開源商業化方面的實踐經驗不足,采取的開源商業策略單一,企業多面臨“技術業務兩張皮”的困境,尚未實現諸如微軟Office365 Copilot、ChatGPT企業版等對企產品的商業化落地,難以搭建起可持續的大模型下游開源商業生態。目前,按照交易量收取費用、定制開發收取費用是國產大模型產品主要收費模式,這些商業模式難以覆蓋大模型開發所需的巨大算力及人力成本,且多為一次性付費,致使與軟硬件生態之間的開源協作受阻。
開源支持體系建設水平較低
目前,我國從大模型開發、訓練到應用的全鏈條開源支持體系水平較低,不利于集中優勢力量,阻礙了技術突破的步伐。在開源開發平臺方面,我國Gitee、GitLink、AtomGit等開源代碼托管平臺發展尚不完善。例如,國內Gitee等代碼托管平臺因網絡及設備故障而導致用戶存儲代碼丟失的大型故障時有發生,且維護不透明,運營穩定性較差,因此難以維持用戶使用黏性;而國外的美國Github專門有網站記錄所有故障及修復時間,穩定的運營機制極大增強了用戶信任度,從而促進了用戶的使用量。這一差距充分反映在訪問統計數據上,我國開源代碼托管平臺Gitee的每月訪問量為800萬次,美國Github平臺則高達4.32億次。在開源測試和訓練平臺方面,國際流行的人工智能開源模型庫和社區平臺Hugging Face發展至今已集成了超過50萬具備圖像識別、語音生成、文本生成等多種功能的開源大模型和超過11萬包含多種數據類型的高質量開源數據集,有全球超過5萬家組織使用該平臺,形成了較為成熟的大模型開源工具平臺生態。然而,我國類似的開源平臺發展仍處于初級階段,ModelScope魔搭開源平臺不僅公布的數據集、模型質量參差不齊,部分有較多漏洞,難以進一步開發優化或直接應用,而且開源共建水平較低,如ModelScope魔搭社區開源的2 158個模型中接近60%的模型由排名前10位的貢獻者捐出,超1/3模型由阿里巴巴達摩院一家貢獻。大模型開源代碼托管、訓練、測試平臺的低水平致使國產大模型往往托管在國外平臺上,造成我國大模型的訓練環境和應用場景流失在國外,難以保留在國內,不利于自主發展。在開源治理協調平臺方面,我國相關治理機構缺乏與業界的及時深度交流,導致對開源大模型中涉及的“開源”認定、版權歸屬界定等關鍵問題認知不足,難以在負責任開源大模型生態建設過程中發揮引導和平衡作用。同時,開源基金會等開源促進組織發展尚處于初級階段,開源項目運營經驗不足,運營能力欠缺,難以有效支持大模型開源項目的持續發展。
我國構建大模型開源創新生態的建議
我國應充分吸收開源創新生態構建經驗,秉持開源開放的理念構建大模型開源創新生態,推動大模型全產業鏈的繁榮有序發展。一方面,政府要處理好打造大模型開源生態過程中政府和市場之間的關系,相關部委要明確職責,形成政策合力。另一方面,社會要建立起對開源的合理認知,通過數字公共品制度等探索構建符合大模型產業特性的開源治理體系,推動形成涵蓋大模型上下游全產業鏈的健康開源創新生態,促進大模型產業創新與可持續發展。具體包括以下4個方面。
加強頂層設計,明確各個部門職責
建議效仿中央科技委員會統籌全國科技發展總體部署的機制,國家層面建立統籌大模型發展的組織或機制。明確中央網絡安全和信息化委員會辦公室、國家發展和改革委員會、工業和信息化部、科學技術部、教育部、國家數據局等相關部委在大模型及上下游產業鏈各環節發展中的具體職責,并進行有效統籌。持續關注大模型產業及上下游發展需求,為打造可持續的大模型開源創新生態提供協同有差異的政策支持與資源保障,形成合力促進大模型產業發展。
以數據、算力和算法為抓手補短板、固底板,推動產學研持續投入大模型開源技術研發。建議由中央網絡安全和信息化委員會辦公室、工業和信息化部負責大模型產業培育引導,科學技術部、中國科學院、教育部等合作推動大模型底層技術及原理研究,培養產業發展所需的人工智能架構設計方面人才,國家發展和改革委員會牽頭地方政府做好算力中心、跨區域算力網絡的建設及運營;數據局厘清數據產權、數據資產評估等相關阻礙數據產業鏈發展的相關問題,推動上游數據產業鏈繁榮有序健康發展。
打造共享的大模型研發基礎體系
建設開放國家算力平臺支持大模型訓練。解決跨數據中心算力協同面臨的相關體制機制挑戰,提高各地已有智算中心的利用率和使用效率。推動國家實驗室算力平臺向社會開放,支持組建算力聯盟引導算力開放,集中高檔GPU算力資源,降低各類大模型研發訓練成本。設立國家級開源項目推動頭部科技企業搭建公共大模型基礎平臺、構建低代碼開發工具,促進上、中、下游企業間的協同創新。加快落實《算力基礎設施高質量發展行動計劃》,發揮算力對大模型發展的驅動作用。
推動建立國產智算芯片開源編譯生態。統一各國產智算芯片編譯環境接口,構建類CUDA平臺打通硬件和AI訓練之間的中間軟件層,加大對適應人工智能計算所具有的計算密度高、需要大量低精度計算等特點的軟硬件協同設計研發。這能夠降低采用不同GPU進行大模型訓練時額外的學習成本,有利于大模型發展。同時開源所匯聚的合力能降低芯片廠家的開發成本,促進算力領域技術研發,加快國產GPU芯片發展。注重與國內硬件生態連接,形成軟硬件有效協同,提升產業創新體系整體效能。通過設立大模型開源大基金等方式,推動國產大模型開源軟硬件生態發展,形成基礎軟硬件與大模型有效協同。
促進開放數據體系建設。發揮國家數據局的統一協調作用構建高質量數據集,擴大政府開放數據范圍并通過建立多層次數據開放體系加強數據交換共享,形成大模型發展的開放數據支撐。加快構建有利于促進大模型產業發展的數據版權制度,借鑒國外大模型訓練版權責任豁免機制,探索實現更為邏輯周密和利益平衡的數據版權規則設計。
強化全產業鏈開源開放體系建設
加強大模型相關全產業鏈生態布局,推動大模型開發、訓練、應用全鏈條支撐平臺有組織地建設,由中立的組織機構主導、科技企業參與大模型產業創新生態基礎層和模型層的開源,由科技企業主導大模型產業創新生態中間層和應用層的開源。
從產業生態的角度引導推動大模型產業應用落地。全面調研和布局大模型相關的產業鏈,促進開源大模型在行業核心應用場景如生物醫藥、智能化教育教學、智能制造等領域進行應用示范,推動開發各類新型應用場景,支持AI創新企業采用公共算力開發行業智能應用,引導行業用戶與大模型廠商合作,推動各行業智能化升級。
加強面向開源代碼的計算和訓練型大模型平臺的設計開發和推廣。對標GitHub和Hugging Face等建設利于大模型開發、測試和訓練的開源平臺,開展我國開源平臺建設工作,助力大模型的利用和推廣。發揮開源基金會或新型研發機構作用,引導企業依托國內代碼托管平臺開源一批具有行業影響力的軟件項目,積極培育我國開源生態環境。
探索新型大模型商業開源運營機制。借鑒OpenAI的“非營利性機構+有限入股營利回報”模式,加強市場主導和產業政策支撐共同推進基礎大模型市場建設,構建可持續的開源創新成果商業模式。
鼓勵社會資本參與開源大模型技術的產業投資。推動社會資本參與大模型產業的風險投資和產業投資,探索建立線下孵化器空間,聯合開源社區及代碼托管平臺共同打造線上線下融合、極具活力的開發者社區,促進開源大模型下游商業生態繁榮發展。
完善開源創新治理體系鼓勵發展
推動商業開源政策研究。研究制定有利于開源商業化實施的相關政策,推動建成公眾貢獻數據和使用數據行業規范等數字公共產品制度,強化開源許可證的法律效力,有力保護開源成果知識產權,將“開源不等于免費”的開源理念貫徹到大模型產學研用全過程。研究制定實驗室開源大模型開源許可機制,針對開源社區上不同類型下游開發者和用戶,打造不同開源層級的許可協議,授權開源使用。推動開源產業發展,以稅收優惠等方式鼓勵企業積極探索開源,參與開源生態建設,深入了解開源回饋方式,尋找有效的基于開源的商業反饋模式。
推動開源社區治理水平提升。持續支持國內開源基金會、開源社區等開源力量發展,推動開源文化理念在社會的廣泛傳播。提高開源社區運營水平,運用大數據分析手段精確評估社區內參與合作者的貢獻情況,精準識別社區內核心開源貢獻者并予以獎勵,形成良好的“貢獻-承認”正向反饋循環。完善大模型開源評價、安全評估框架等監測機制,以推動大模型產業良性健康發展。
推動大模型開源國際交流合作。打造具有國際先進技術水平的大模型開源開放平臺,并加強與國際溝通大模型倫理治理,參與探討制定國際標準。鼓勵企業融入國際頂尖開源社區、參與開源規則制定等,通過開源爭取全球智慧。依托開源社區,加強大模型技術人才自主培養和國際交流,推動高校、科研院所與企業培育更多有熱情做開源貢獻的人才。
(作者:溫馨、馮澤,中國科學院科技戰略咨詢研究院;張超,上海交通大學國家戰略研究院;郭銳、陳凱華,中國科學院大學公共政策與管理學院;朱其罡,上海開源信息技術協會 對外經濟貿易大學;編審:金婷;《中國科學院院刊》供稿)





